Data centres have huge water footprints with the growth of Artificial Intelligence
The Artificial Intelligence Crisis: How the AI is Changing Science, How Science Is Proving Its Importance and How Commercial Forces Are Using It
A debacle at OpenAI has highlighted concerns that commercial forces are acting against responsible development of AI. The company that built ChatGPT suddenly fired its co-founder and chief executive Sam Altman on 17 November, only to reinstate him five days later, after staff revolted. “The push to retain dominance is leading to toxic competition,” says Sarah Myers West at the AI Now Institute. She is concerned that the appearance of products will cause them to be confused by their use and misuse. “We need to start by enforcing the laws we have right now,” she says.
Earlier this year, an image of the pope wearing a huge puffer jacket went viral — and many people didn’t realize it was generated using AI. Scientists are trying to stop shallowfakes. The Nature’s collection contains stories about how artificial intelligence is changing science. Seor Salme did the drawing.
AI tools, methods and data generation are advancing faster than institutional processes for ensuring quality science and accurate results. The scientific community must take immediate action or risk wasting research funds and compromising trust in science as artificial intelligence develops.
Keeping an AI eye: How to build a data centre without worrying about the cost of building a robot with plastic skins and soft muscles
A 3D printer can be used to create complex designs, which include a robotic hand with soft plastic muscles and rigid plastic bones. Combining different materials in the same print run is difficult. It’s possible to build 3D structures by spraying layer after layer of material. It keeps an electronic eye on any accidental lumps or bumps and compensates for them in the next layer. This removes the need for messy mechanical smoothing, which usually limits the materials that can be used.
The Japanese habit of showing respect to non-living things, including AI, demonstrates one path towards a more balanced relationship with our gadgets — and is not a sign of unhealthy anthropomorphism, argues AI ethicist and anthropologist Shoko Suzuki. 5 min read.
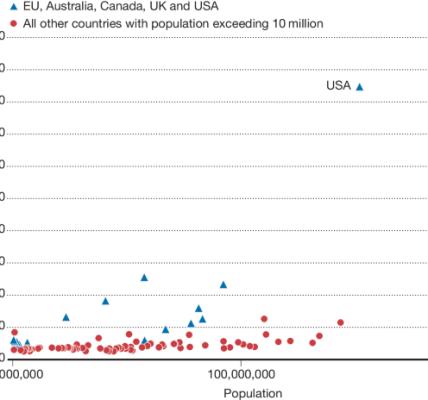
‘Thirsty’ computing hubs could put pressure on already stretched water resources in sub-Saharan Africa and other regions where drinking water is scarce. Data centers that power Artificial Intelligence have a large water footprint due to the amount of electricity they use. Yet water scarcity is rarely considered when deciding where to build data centres, says computer scientist Mohammad Atiqul Islam, co-author of a study of the problem. “Typically, companies care more about performance and cost.”
Source: Daily briefing: Data centres’ huge ‘water footprint’ becomes clear amid AI boom
The Rise of Artificial Intelligence in Earth and Space Science: Finding the Right Repository for the Right Research Needs, Not Just Using the GPT-4
The GPT-4 can be used to create fake clinical-trial data to back up a scientific claim. The results of two surgical treatments were compared and it was found that one procedure is better than the other. In real trials, the two lead to similar outcomes. The data doesn’t hold up to close scrutiny by authenticity experts, but it looks like a real data set to an untrained eye.
Several agents can work together to solve chess puzzles. Researchers tried to create up to ten different versions of the chess game, each trained for different strategies. A computer program decides who has the best chance of succeeding. According to an Artificial Intelligence researcher, the system was capable ofSolving more chess puzzles than AlphaZero alone, and that’s because of the artificial brainstorming session.
Many of the research libraries don’t accept new data. The most valuable repositories are those that have long-term funding for storage and curation, and accept data globally, such as GenBan, the Protein Data Bank and the EarthScope Consortium (for seismological and geodetic data). Each is part of an international collaboration network. Some repositories are funded, but are restricted to data derived from the funder’s (or country’s) grants; others have short-term funding or require a deposition fee. This complex landscape, the various restrictions on deposition and the fact that not all disciplines have an appropriate, curated, field-specific repository all contribute to driving users towards generalist repositories, which compounds the risks with AI models.
The rise of AI in the field is clear from tracking abstracts5 at the annual conference of the American Geophysical Union (AGU) — which typically gathers some 25,000 Earth and space scientists from more than 100 countries. The number of abstracts that mention AI or ML has increased more than tenfold between 2015 and 2022: from less than 100 to around 1,200 (that is, from 0.4% to more than 6%; see ‘Growing AI use in Earth and space science’)6.
Yet, despite its power, AI also comes with risks. These include misapplication by researchers who are unfamiliar with the details, and the use of poorly trained models or badly designed input data sets, which deliver unreliable results and can even cause unintended harm. For example, if reports of weather events — such as tornadoes — are used to build a predictive tool, the training data are likely to be biased towards heavily populated regions, where more events are observed and reported. The model is likely to over- predict tornadoes in urban areas and under predict them in rural areas, leading to unsuitable responses.
- Risk. Consider and manage the risks and biases that data sets are susceptible to, as well as how they might affect the outcomes or have consequences.
Community Report: AI Applied to Environmental and Social-Science Data in High-Dimensional Areas, Regions, and Communities
More detailed recommendations are available in the community report6 facilitated by the American Geophysical Union, and are organized into modules for ease of distribution, use in teaching and continued improvement.
For example, many environmental data have better coverage or fidelity in some regions or communities than in others. Tropical rainforests, for instance, or areas with fewer in situ sensors will be less well represented. Similar disparities across regions and communities exist for health and social-science data.
The abundance and quality of data sets are known to be biased, often unintentionally, towards wealthier areas and populations and against vulnerable or marginalized communities, including those that have historically been discriminated against7,8. In health data, for instance, AI-based dermatology algorithms have been shown to diagnose skin lesions and rashes less accurately in Black people than in white people, because the models are trained on data predominantly collected from white populations8.
Such problems can be exacerbated when data sources are combined — as is often required to provide actionable advice to the public, businesses and policymakers. Assessing the impact of air pollution9 or urban heat10 on the health of communities, for example, relies on environmental data as well as on economic, health or social-science data.
Unintended harmful outcomes can occur when confidential information is revealed, such as the location of protected resources or endangered species. The risks of attacks on data without researchers being aware are increasing as more data sets are being used. AI and ML tools can be used maliciously, fraudulently or in error — all of which can be difficult to detect. Noise or interference can be added, inadvertently or on purpose, to public data sets made up of images or other content. This can make the conclusions that can be found more difficult to draw. Furthermore, outcomes from one AI or ML model can serve as input for another, which multiplies their value but also multiplies the risks through error propagation.
Classical model studies usually require researchers to provide access to the underlying code and any relevant specifications. Protocols for reporting limitations and assumptions for AI models are not yet well established, however. AI tools often lack explainability — that is, transparency and interpretability of their programs. It’s difficult to understand how a result was obtained, what the uncertainty is, or why different models give different results. Moreover, the inherent learning step in ML means that, even when the same algorithms are used with identical training data, different implementations might not replicate results exactly. They should come up with results that are similar.
Researchers and developers are working to make the behavior of artificial intelligence understandable to users. Artificial Intelligence can analyse huge volumes of remote- sensed observations, thus improving the forecasting of severe weather dangers. Clear explanations of how outputs were reached are crucial to enable humans to assess the validity and usefulness of the forecasts, and to decide whether to alert the public or use the output in other AI models to predict the likelihood and extent of fires or floods2.
In Earth sciences, Xai attempts to quantify or visualize which input data featured more or less in reaching the model’s outputs in any given task. Researchers should examine these explanations and ensure that they are reasonable.
Research teams should include members of the community who can be involved in providing data or who might be affected by research results, as well as specialists in each type of data used. One example is an AI-based project that combined Traditional Knowledge from Indigenous people in Canada with data collected using non-Indigenous approaches to identify areas that were best suited to aquaculture (see go.nature.com/46yqmdr).
Quality checks and the ability to add information about data limitations are provided by leading discipline-specific repositories. According to our findings, the data requirements set by funders and journals has inadvertently caused researchers to adopt free quick and easy solutions for their data sets. Generalist repositories that instantly register the data set with a digital object identifier (DOI) and generate a supporting web page (landing page) are increasingly being used. Due to the fact that different types of data are gathered, it is hard to trace and impede automated access.
This trend is evident from data for papers published in all journals of the AGU5, which implemented deposition policies in 2019 and started enforcing them in 2020. Zenodo and fig share are two generalist repositories where most publication-related data has been deposited. Digital Science is part of Holtzbrinck, which is a majority shareholder in Springer Nature. Many institutions maintain their own generalist repositories, again often without discipline-specific, community-vetted curation practices.
Disciplinary repositories, as well as a few generalist ones, provide this service — but it takes trained staff and time, usually several weeks at least. Data deposition must therefore be planned well before the potential acceptance of a paper by a journal.
Source: Garbage in, garbage out: mitigating risks and maximizing benefits of AI in research
Sustained Investments for Research Repositories and Compliance With New Mandates16: a case study in the RHIC/SIGMA collaboration
Sustained financial investments from funders, governments and institutions — that do not detract from research funds — are needed to keep suitable repositories running, and even just to comply with new mandates16.