Automated Atlas of Human Neural Organoid Cells Using a Large-Scale Bioinformatics Data Atlas
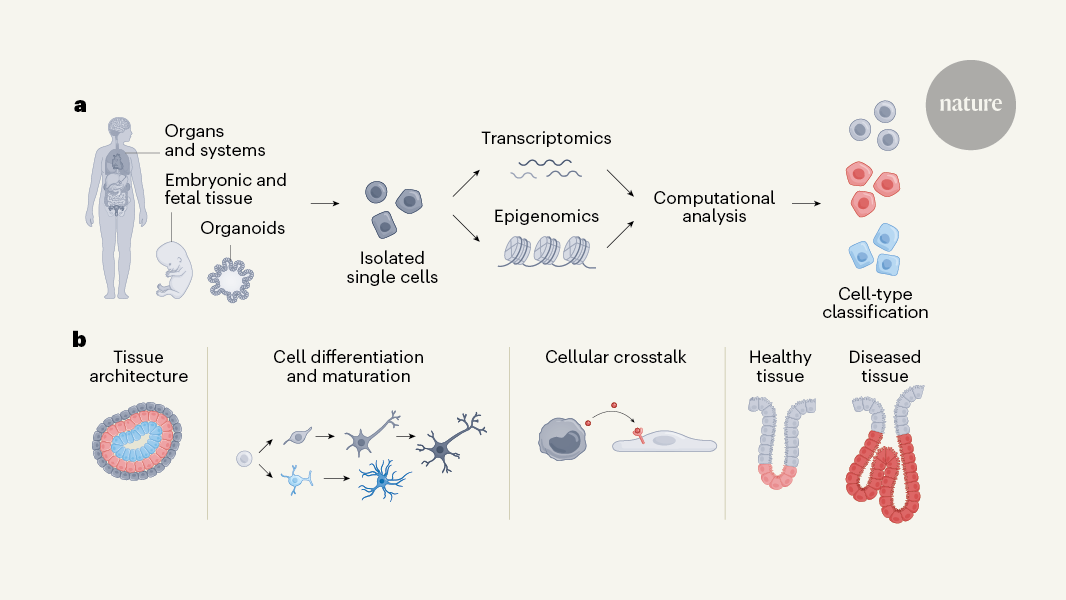
An ambitious project to chart a map of all human cell types across tissues and throughout the stages of life was initiated by the HCA consortium nearly a decade ago. Mapping such complexity is challenging11 because of shifting technologies, variability between experiments and inherent noise in sparse data that results from having small amounts of biological material to work with. The constant change in cell states and the rise in omics data complicate the identification and classification of cells. If these issues are not handled adequately, biological interpretations can be compromised, highlighting the need for techniques that robustly correct errors and integrate data from different modalities11–13. A surge in methods that deal with specific challenges has led to a future where models can be further standardize and refine their complexity for optimal performance. Three machine-learning algorithms, developed by researchers in the HCA consortium, address cell annotation and data integration.
Oliver et al.2 describe the GI tract in an Atlas of Gastrointestinal Tracts. Many previous data sets have been created, but the present atlas deftly integrates these — using an innovative computational approach — into a large-scale atlas of 1.1 million cells, along with annotations of the resident cell types and states. The data sets from the individuals with inflammatory diseases are on top of the atlas. Metaplasia can be caused by inflammation and can be a switch between one type of cell and another. By studying the data sets the authors inferred the origin of these metaplastic cells by comparing them with stem cells. This insight highlights the benefit of the atlas’s completeness, which allows for the comparison of disease states in one organ with the normal states of cells in different organs.
organoids are a powerful model for functional analysis because they are so tractable. The human neural organoid cell atlas described by He et al.3 is built on 1.7 million cells by integrating 36 single-cell RNA-sequencing data sets, generated with 26 protocols for producing organoids from cultured cells. The question of how organoids capture certain aspects of the developing brain has already been explained in the atlas. The authors found a correspondence between the length of time the organoids were in culture and the developmental stages that they resemble in the human brain: in the first three months of culture, the organoid resembles the cellular state of the fetal brain during the first trimester of pregnancy, whereas in the next three months, it resembles the second trimester. But the authors found a limit to the correspondence. The diversification in neuronal cell types that occurs with development did not continue in the organoid, and the fetal brain during the last trimester of pregnancy was not captured — leaving an open question about which required signals or other features are missing from organoid models.
The map was created by Yayon and his team to show the early fetal development and early postnatal stages of the immune cells in the left side of the chest. Using the spatial dimension, the authors conceived of a ‘common coordinate framework’ to mathematically map the tissue. This model of the axis between the outer part of the thymus and its centre (the cortico-medullary axis) allows for a deeper understanding of tissue organization and comparison of the organ both in and between individuals. It will be interesting to study how this atlas extends to other stages of life, such as old age.
The formation of tissues, the development of organs and the establishment of body functions are all achieved by the coordinated self-organizing of continuously differentiating cells. Scientists don’t have a good sense of the mechanisms that underlie such development in humans.
They studied the development of parts of the skull and joints after a baby is born. Through the simultaneous mapping of transcriptomic and epigenomic profiles of single cells, they identified key gene-regulatory networks that direct the commitment of cells to chondrogenic (cartilage-forming) and osteogenic (bone-forming) lineages. The authors inferred probable lineage relationships along differentiation pathways and propose how cellular crosstalk might guide the formation of bone, identifying a potential key role for interactions with the vascular system. The authors combined genome wide association studies with their single cell analysis to identify cells that may be linked toOsteoarthritis, a disease that affects the joints.
The comprehensive cellular atlas of skin development is presented by Gopee and colleagues. Using a combination of single-cell and spatial transcriptomic technologies, the authors mapped dynamic changes in cell states and detail how these cells organize to form developmental structures and interact in microanatomical skin niches. Their findings highlight the unexpectedly diverse role of immune cells in coordinating developmental processes, particularly the involvement of macrophages in the formation of blood vessels by endothelial cells. This was further validated through an innovative organoid system that recapitulates key aspects of skin development.
Ergen et al.18 introduce popV, a model for classifying cell types that focuses on transferring cell-type labels from annotated atlases to unannotated data sets. The popV model combines predictions from existing models to produce cells-type labels and uncertainty scores that reflect the degree of disagreement between the underlying tools. The approach highlights ambiguous cases which reduces manual review, and draws attention to cell populations that are challenging to classify. This feature enhances the interpretability of results and streamlines the overall annotation process by reducing the load on researchers, making popV adaptable to future models.
Schuster et al.20 describe the idea of MultiDGD, which involves integrating data from multiple sources using a deep variable model. This type of machine learning uses hidden variables to learn complex patterns — in this case, multiDGD learns optimal hidden-variable representations that are shared across multiple data modalities (transcriptomic and epigenomic), without the need to pre-define important features. By incorporating information about potentially confounding variables, such as inconsistencies between samples, multiDGD enables post-hoc data integration across data sets, making it suitable for multi-omics studies, in which data were gathered from different sources. This model’s clustering of shared representations improves the alignment of multimodal data, enabling associations between genes and regulatory regions of the genome to be mapped — an essential step in understanding gene-regulatory networks.
PopV and scTab lead efforts for standardized annotation and consensus building, whereas multiDGD opens up opportunities for data integration across complex multimodal data sets.
This does not lessen the impact of these methods, but rather highlights the field’s rapid pace and the importance of innovation. To meet this growth, future research is likely to emphasize adaptable and interoperable solutions. These methods contribute valuable foundations for future advancements, paving the way for even more adaptable and scalable models for single-cell, multi-omics data.
The Human Cell Atlas: Where do we stand? Where are we, where are we going? How do we continue to improve the human cell Atlas?
Coming less than a decade after its launch, the studies emerging from the global project are a major achievement. Funders should keep getting funding for the long haul.
There are differences in the lungs of people who died from COVID-19 and the other lung diseases found in the lung cell atlas. The development of the skin and joints of pregnant humans have been studied by scientists.
The HCA would not have been possible without earlier projects, notably the Human Genome Project and, more recently, the NIH BRAIN Initiative, as well as ENCODE, a project to build a ‘parts list’ of functional elements in the human genome. The data the HCA teams have been working on reflects human diversity. The consortium includes scientists from Africa, Asia, Latin America and the Middle East5. Researchers from these regions were invited not only to join, but also to help lead and coordinate HCA projects, and to do so according to priorities relevant to local populations. The initiative now involves more than 3,000 scientists across some 1,700 institutions, recording and studying data from people in around 100 countries.
Most research projects have limited lifespans. It is considered generous for someone to be alive for ten years. A handful of projects might last a few years longer. Permanent funding tends to be reserved for projects of national or international importance, including essential infrastructure — the tools and technologies without which vital discoveries and inventions would not be possible. That is what the HCA needs to be compared to.
Active Cells of Disease Associated Variants: A Critical Account of Genetics and Genomic Impact on Disease Control and Diagnosis in the Human Genome
“While genetic studies have mapped more than 100,000 disease-associated variants in the human genome, we do not know in which cells the majority of these variants are active,” HCA researchers write6. Without this knowledge we can’t fully understand biology, study powerful models of disease, deploy better diagnostics, and develop more effective therapies.

