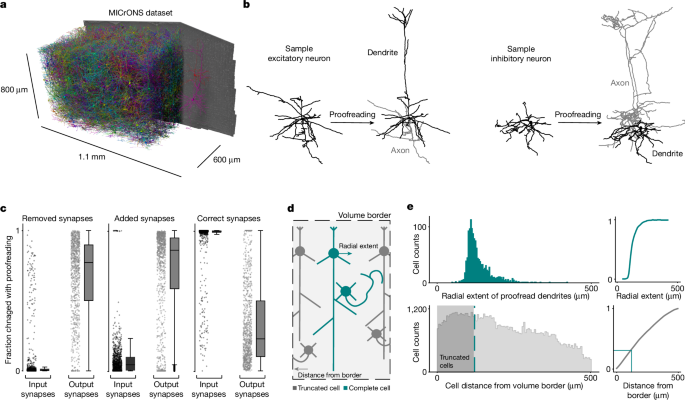
On-demand deep learning and automated proofreading for a complete serial-section electron microscopy dataset of the postnatal day 87 mouse
This dataset consists of a 1.1 mm × 800 µm × 600 µm segmentation of a volumetric serial-section electron microscopy dataset from mouse visual cortex of a male postnatal day 87 (P87) mouse. The dataset covers all layers of cortex and spans primary visual cortex and two higher visual areas. The data has been described. electron microscopy was then carried out on the mouse after two photon images were done. The specimen was sectioned and imaged. The images were aligned through a process of deep learning and manual proofreading.
Five expert neuroanatomists used two different versions of the Connectome Annotation Versioning Engine and a modified version of Neuroglancer58 to proofreading. Proofreading was aided by on-demand highlighting of branch points and tips on user-defined regions of a neuron based on rapid skeletonization (https://github.com/AllenInstitute/Guidebook). This approach quickly directed proofreader attention to potential false merges and locations for extension, as well as allowing a clear record of regions of an arbour that had been evaluated.
All the cells were identified in the columnar volume using these boundaries and previous nucleus centroids. A brief manual examination and recheck was used for assigning coarse cell classes, which included excittory, inhibitory, and non-neuronal. To facilitate concurrent analysis and proofreading, we split all false merges connecting any column neurons to other cells (as defined by detected nuclei) before continuing with other work.
For inhibitory axons, we began by ‘cleaning’ axons of false merges by looking at all branch points. We emphasized all the thick branches that were well suited to project to new regions when we extended axonal tips. Once the primary branches have been cleaned and established, we followed many of the tips that were given to us. The tips were extended to the point of completion or misunderstanding for those with one of the two polarities. Axon proofreading time differed significantly by cell type not only because of differential total axon length but also because of axon thickness differences that resulted in differential quality of autosegmentations, with thicker axons being of higher initial quality. Typically, inhibitory axon cleaning and extension took 3–10 h per neuron.
Basket cells were recognized as cells that made more than 20% of their synaptic inputs onto the soma or proximal dendrites of cells. The low density of output synapses and boutons that often had no post-synaptic structures are recognized by neuralgiaform cells. Bipolar cells were labelled by having only 2 or 3 primary dendrites, and primarily making synapses with other inhibitory neurons. The label Martinotti/non-Martinotti was given to cells that have previously been described in the literature to target the excitatory dendrite of excitatory neurons without displaying hallmark features.
The Distribution of Postsynaptic Cellular Densities across Dendritic Skeletal Vertices in the MICrONS Dataset
There were few errors, and thus the training set was augmented with manually labeled errors that came from the entire dataset.
Median radius across dendritic skeleton vertices. To avoid the region immediately around the soma from having a potential outlier effect, we only considered skeleton vertices at least 30 µm from the soma.
Changes in nucleus and soma size features were noticed due to differences in sample preparation thickness. Changes in section thickness across the dataset is what appears to have caused this. The entire dataset had to be binned by the longest length scale for which there was no apparent systematic shift in the distribution in the Z plane and normalized by the average within each bin.
To measure the predicted cell densities per subclass across the MICrONS dataset, we divided the dataset into 50-µm2 bins in the x–z plane. We calculated the number of cells in each subclass and scaled that value to the number per square millimetres to make comparisons between densities reported in literature.
To quantify whether a given cell was a chandelier or not, we measured the angle (ϕ) and the distance (r) between every output synapse and the soma of the postsynaptic cell (Fig. 6c). A synapse with an angle value of 0° would be considered to be directly above the target soma whereas one with an angle of 180° would be considered to be below it. Owing to variations in axon directionality with respect to the pial surface, we considered synapses with angle values between 160° and 180° and within 60 µm of the soma to be on the AIS of the target soma. In fact, because the specificity of chandelier targeting is so high, the density of synapse angle distributions alone was enough to identify other chandelier cells (Fig. 6e). On inspection of the proofread 20 nearest neighbours, we determined that cells with more than 40% of their synapses within 160–180° were chandelier cells. The average normalized density for the identified cells was 62% as compared to 8% for the non-chandelier cells. The significance of the random cell population to the nearest neighbours was tested with a Fisher exact test.
To characterize the distribution of synaptic inputs relative to the cell body instead of cortical space, we computed the number of synapses in 13 soma-adjusted depth bins starting 100 µm above and below the soma. The top five components using SparsePCA were the same as before. The loadings for each of these components were used as further features.
The top level of the hierarchy distinguishes non- neurals from neurals. The cross-validated accuracy score on the column was over 100% with the test score over 98%. The second level of the model simply distinguished excitatory from inhibitory neurons. Here, the column cross-validated accuracy score was 98.3% and the test set was 85%. Across all subclasses, the hierarchical model on the column had cross-validated accuracy of 91% and a dataset-wide test set accuracy of 82%.
For each classifier, the model type was chosen using a randomized grid search for the following models: support vector machine with a linear kernel, support vector machine with a radial basis function kernel, nearest neighbours, random forest classifier, decision tree and neural network. 50 models were trained with different parameters and the top-performing model was chosen. Individual models were further optimized using tenfold cross-verification to evaluate accuracy and F1 score. Training and test examples were held consistent across models for direct performance comparison within each level.
Convolutional Networks and Surface Segmentation for 2D UMAP Classification of the MICrONS dataset based on Automatic Detection of Synapse Size
The pre- and postsynaptic meshes in the EM dataset were previously detected. These data also included the automatically detected synapse size (number of voxels per synapse)66. In brief, a convolutional network was trained to identify synaptic clefts and assign voxels to each side of the cleft. The MICrONS volume was calculated using methods described in Wu et al.65. Subsequently, a second convolutional network was trained to perform pre- and postsynaptic partner assignment for the voxels for each detected synaptic cleft66. At the dataset level, manual inspection of the algorithmically identified synapses across subvolumes provides an estimated precision of 97% (correctly identifying a synapse) and recall of 89% (identifying all synapses)23.
Around each synapse, we extracted a 3,500-nm region to obtain the synapse region mesh. We experimented with region cutouts between 1,000 and 5,000 nm; however, smaller cutouts led to ambiguities in the main shaft identification and thereby produced errors in the subsequent skeletonization. At 3,500 nm, the skeletons were more stable and segmented as expected. This mesh was then segmented using the CGAL surface segmentation algorithm59, which splits regions on the basis of differences in thickness. We adapted our method to use a local skeleton instead of a precomputed mesh to identify the PSS region. This gave us the freedom to modify this method without the need for a second opinion.
All features need to be placed in the same scales for 2D UMAP training. For this reason, we independently z-scored each feature across all cells and used that as the input for classifier training as well as the UMAP embeddings in Figs. 3–6.
Non-parametric comparisons across MET-types and gene expression in the neurons of Sst Calb2, Ptdg4Myh8 and Etv
Comparisons across several MET-types were performed using non-parametric Kruskal–Wallis tests followed by Conover post hoc tests with Bonferroni corrections for pairwise comparisons. P values are indicated on plots if the Kruskal–Wallis P values < 0.05 and post hoc tests for pairwise comparisons are P < 0.05 or P < 0.01. There are errors reported. Unless otherwise stated. The fraction of cell types targeted by the MET-type was compared with the fraction of other cell types using a non-parametric test with a false discovery rate. Boxplot whiskers indicate the range (maximum/minimum) of data; n = 173 inhibitory neurons from the EM dataset; n = 16 extended MCs and, of those, n = 3 were predicted to be MET-8, n = 6 were predicted to be MET-4 and n = 5 were predicted to be MET-6. Measurements are taken repeatedly from these cells.
We analysed differentially expressed genes using scrattch.hicat (https://github.com/AllenInstitute/scrattch.hicat/tree/master) on the reference fluorescence-activated cell sorting-collected single-cell RNA sequencing dataset6 to compare the main transcriptomic types that make up each MET-type (MET-8: MET-4 was the Sst Hpse Cbln4. Sst Calb2 Necab1and Sst Calb2 Pdlim5; MET-6: Sst Chrna2 Glra3, Sst Chrna2 Ptdg4 Myh8 and Etv are related. Pairwise differentially expressed genes were identified as previously described6 using the limma package69 and selecting genes with at least a twofold change in expression and an adjusted P value of less than 0.01. The top five upregulated and downregulated genes for each pairwise comparison were selected for visualization (ranked by adjusted P value). The average expression of these genes and the fraction of cells with non-zero expression was calculated for the neurons of the three Sst MET-types in the Patch-seq data16 and presented as a dot plot. Only genes whose expression is at least 50% in a cell are selected for visualization.
Proportions of MET-types were estimated from a recently published MERFISH dataset67. The cell counts were calculated from the MERFISH dataset. As the cells in the MERFISH dataset were mapped to a whole-brain taxonomy67, whereas the MET-types were based on a VISp-specific taxonomy6, we identified correspondences between t-types across several taxonomies. Correspondences between the original taxonomy of Tasic et al.6 and the cortex or hippocampal formation (CTX/HPF) taxonomy were identified by finding the Tasic et al.6 t-types that had the highest number of shared cells for each CTX/HPF t-type68. There were correspondences between the whole-brain taxonomy and the CTX/HPF. 67. We assigned Tasic et al.6 t-types to the MET-types to which the largest number of cells belonged16, except for the t-type Sst Calb2 Pdlim5, for which corresponding cells were assigned to either Sst MET-3 (if located in L4 or above) or Sst MET-4 (if located in L2/3). The Sst MET-1 cells were not analysed here. The original study contained a small amount of cells but no clear t-type correspondences have been found for the MET-type Sst MET-11.
Annotators visualized all the outputs from a given presynaptic cell using annotators. The regions without synaptics were manually inspected. If myelination was seen, an annotator marked the start and end point of each myelinated segment in Neuroglancer to generate a line. The number of these annotations was summed to determine the number of myelinated segments per cell. The length of the annotations was summed to determine the myelinated axon per cell.
Cell subclass identities were assigned to all meshes with single somas (individual cells) in the EM dataset using a support vector machine classifier trained on somatic and nuclear features60. To get predictions for cell type identities, the classifier was applied to the EM dataset. In all plots shown above, we use assigned types. There was broad agreement between the automated and manual cell typing except for a specific disagreement of L2/3 versus L4 identity for targets of the predicted MET-8 cell type due to differences in layer boundaries used by manual versus automated methods (Extended Data Fig. 5b). Labels shown in the figures are from automated assignment.
The mean and s.d. of the Patch-seq data were used to calculate the Z scores for the morphological features.
A reliability metric was quantified as the fraction of iterations each sample was predicted as its final MET assignment out of all predictions (for example, a cell was predicted into this MET-type 80% of the time). To determine an appropriate threshold, we explored reliability scores in the Patch-seq data. We applied random subsampling iterations in a leave-one-out manner to the Patch-seq data. Here we set one Patch-seq sample aside and use the rest as training data. In each iteration, the training data are sub-sampled randomly as described above and used to fit a new RFC. The classifier predicts the MET-type label of the single left-out Patch-seq sample. For every Patch-seq cell, 500 times had been repeated until each had a predicted label and a reliability metric. We then plotted a cumulative histogram of the correctly and incorrectly predicted labels versus the reliability score. It was found that the most inclusive value for Patch-seq samples is a reliability score of more than 5. 2a).
The results of the assessment of the performance on the prediction of MET-type labels for Patch-seq cells was based on the features of inhibitory cells in the previously published dataset. Specifically, we used a stratified fivefold cross-validation approach to assess classification accuracy. The data were split randomly into five partitions while maintaining the distribution of MET-type labels in each partition. This method iteratively rotates which partition is withheld from training and used to validate the model. The MET-types that had less than five reconstructions were not included. A maximum depth of 10, balanced class weights, minimum of ten samples per split and at least five samples per leaf was found to be superior to other models. Fivefold cross-validation with shuffling was repeated twenty times and achieved a mean accuracy far above the expected chance accuracy for 22 categories. The model predicted the MET label of held out data more frequently than it did not in the course of training. 5b). The overall F1 score was calculated using an average of F1 scores for each MET-type, and a categorization of that type versus any other type. The matrix for data hold-out validation was recorded. 1c.
Number of distinct branches and median of inhibitory cells based on branch versus distance in a connectomic census of mouse visual cortex (An ab initio study)
We measured the number of distinct branches based on distance from the soma at ten, every 30 m starting at 30 m and continuing to 300 m. To find the number of branches that were relative to precise point locations, the number of connected components was found in a subgraph formed around the 10 m line. We computed the top three singular value components of the matrix on the basis of branch count versus distance for all excitatory neurons, and the loadings were used as features.
Because the fraction of synapses targeting all compartments sums to one, the last remaining property, synapses onto distal basal dendrites, was not independent and thus was measured but not included as a feature. It was found through inspection of the data that two further properties were associated with synaptic output.
The fraction of synapses that are part of multisynaptic connections, those with at least two synapses between the same presynaptic neuron and target neuron.
Using these six features, we trained a linear discriminant classifier on cells with manual annotations and applied it to all inhibitory cells. It was not inaccurate to say that differences from manual annotations were a different view of the data.
Median tortuosity of the path from branch tips to soma per cell. The ratio of path length to the distance from the tip to the soma centroid is known as totruosity.
The average linear density of synapses. This was measured by computing the net path length and number of synapses along 50 depth bins from layer 1 to white matter and computing the median. A linear density was found by dividing synapse count by path length per bin, and the median was found across all bins with non-zero path length.
Source: Inhibitory specificity from a connectomic census of mouse visual cortex
Computing the importance of features for excitatory M-types and neurons using a random forest classifier and SMOTE resampling
All features were computed after a rigid rotation of 5 degrees to flatten the pial surface and translation to set the pial surface to 0 on the y axis. Features based on apical classification were not used to avoid ambiguities on the basis of both biology and classification.
To compute the importance of each feature for each M-type, for each M-type we trained a random forest classifier to predict whether a cell belonged to it using scikit-learn78. Because the classes were strongly imbalanced, we used SMOTE resampling to oversample datapoints from the smaller class. The Mean Decrease in Impurity metric is used to quantifies the number of features used in the decision tree ensemble.
First we computed the number of connections across excitatory M-types in the column, then we computed the number of interneurons. The normalized synaptic output budget was then used to create a vector for each of the neuron’s elements. Normalized synaptic output budgets were oversegmented using k-means (k = 20) with Euclidean distances 500 times, and a matrix of coclustering frequency—that is, the number of times two cells were put in the same k-means cluster—between individual cells was computed. A final M-type was found through agglomerative clustering with complete linkage of the coclustering matrix, scanning from two to 25 output clusters and choosing a final value of 18 on the basis of silhouette score and Davies–Bouldin score.
On connectivity cards, we also show a similar selectivity index on the basis of compartment rather than M-type. In that case, the shuffled distribution preserves observed depth and M-type output distributions but not compartments.
Source: Inhibitory specificity from a connectomic census of mouse visual cortex
Automatic cleft identification and synaptic partner assignment in the autoTEMs dataset of the Cerebral Automorphic Neural Network (TEM)
A network was trained to tell whether or not a voxel participates in a synaptic cleft. The methods described in ref were used to processference on the entire dataset. 69 using 8 × 8 × 40 nm3 images. The predictions of clefts were made using connected components and parts smaller than 40 voxels were removed. A separate network was trained to perform synaptic partner assignment by predicting the voxels of the synaptic partners given the synaptic cleft as an attentional signal72. This assignment network was run for each detected cleft, and coordinates of both the presynaptic and postsynaptic partner predictions were logged along with each cleft prediction.
The alignment process isn’t associated with the curved plane making it unlikely that it’s related to distortion in the imagery.
There is no large, correlated distortion in deep layers of the blood vessel, making it likely that it is not a result of mechanical stress. Moreover, it is unclear why such stress would affect only layer 5b and below.
It has been observed in other large EM datasets that the curve in visual cortex is similar to that in light level morphological reconstructions.
The volume assembly pipeline is described in detail elsewhere62,63. Briefly, the images collected by the autoTEMs are first corrected for lens distortion effects using nonlinear transformations computed from a set of 10 × 10 highly overlapping images collected at regular intervals. Point correspondences are obtained using the scale-invariant feature transform and overlapping image pairs are identified in each section. With regularization, the sum of squared distances between the point correspondences between these tile images is estimated per image. A per-section transformation that roughly ties these sections in three dimensions is estimated by a down sample version of these stitched sections. The rough aligned volume is rendered to disk for further fine alignment. The software that is used to stitch and align the datasets can be found in a repository. To be able to align the volume, we had to make the image processing process robust. Cracks larger than 30 um (in 34 sections) were corrected by manually defining transforms. The smaller and more numerous cracks and folds in the dataset were automatically identified using convolutional networks trained on manually labelled samples using 64 × 64 × 40 nm3 resolution images. The same was done to identify voxels containing tissue. The rough alignment was iteratively refined in a coarse-to-fine hierarchy66 using an approach based on a convolutional network to estimate displacements between a pair of images67. The final displacement field for each image was produced by combining the displacement fields of the adjoining sections. The first two images were 1,024 1,024 and then 64 64 40 nm3 images. The composite image of the partial sections was created using the tissue mask previously computed.
This study61 used a fleet of transmission electron microscopes that had been converted to continuous automated operation. It was built on a standard JEOL 1200EXII 120 kV transmission electron microscope that had been modified with customized hardware and software, including an extended column and a custom electron-sensitive scintillator. A single large-format CMOS (complementary metal–oxide–semiconductor) camera outfitted with a low-distortion lens was used to grab image frames at an average speed of 100 ms. The autoTEM was also equipped with a sample stage that offered fast, high-fidelity tissue montaging and a reel-to-reel tape translation system that locates each section using index barcodes. During scanning, the reel-to-reel GridStage moved the tape and found its targets through its barcode. Quality control was performed on the image data that failed the screening.
After optical imaging at Baylor College of Medicine, candidate mice were shipped via overnight air freight to the Allen Institute. The mice were perferried with the fixative mixture of 2.5% paraformaldehyde, 1%glutaraldehyde and 2% calcium chloride in 0.08 M sodium cacodylate buffer. A thick (1,200 µm) slice was cut with a vibratome and post-fixed in perfusate solution for 12–48 h. The slice was washed and prepared for reduced osmium treatment. 64. Unless otherwise stated, the steps were performed at room temperature. The first step in osmication was to have 2% osmium tetroxide with 8% v/v formamide in a 0.1 M sodium cacodylate buffer. Potassium ferricyanide 2.5% (76 mM) in 0.1 M sodium cacodylate, 90 min, was then used to reduce the osmium. The second osmium step had a concentration of 2% in the cacodyle for 150 min. Samples were washed with water and then immersed in thiocarbohydrazide for further intensification of the staining (1% thiocarbohydrazide (94 mM) in water, 40 °C, for 50 min). After washing with water, samples were immersed in a third osmium immersion of 2% in water for 90 min. After extensive washing in water, Walton’s lead aspartate (20 mM lead nitrate in 30 mM aspartate buffer, pH 5.5, 50 °C, 120 min) was used to enhance contrast. After two rounds of water wash steps, samples proceeded through a graded ethanol dehydration series (50%, 70%, 90% w/v in water, 30 min each at 4 °C, then 3 × 100%, 30 min each at room temperature). Two rounds of 100% acetonitrile (30 min each) served as a transitional solvent step before proceeding to epoxy resin (EMS Hard Plus). A progressive resin infiltration series (1:2 resin:acetonitrile (for eample, 33% v/v), 1:1 resin:acetonitrile (50% v/v), 2:1 resin acetonitrile (66% v/v) and then 2 × 100% resin, each step for 24 h or more, on a gyrotary shaker), was done before final embedding in 100% resin in small coffin moulds. After curing at 60 C for 96 h, it was time to unmoulding and mount the sample. The sections were then collected at a nominal thickness of 40 nm using a modified ATUMtome (RMC/Boeckeler61) onto six reels of grid tape61,65.
All animal procedures were approved by the Institutional Animal Care and Use Committee at the Allen Institute for Brain Science or Baylor College of Medicine. A neurological data acquisition was done at the College of Medicine. Afterwards the mice were transferred to the Allen Institute in Seattle and kept in a quarantine facility for 1–3 days, after which they were euthanized and perfused. All results described here are from a single male mouse, age 64 days at onset of experiments, expressing GCaMP6s in excitatory neurons via SLC17a7-Cre and Ai162 heterozygous transgenic lines (recommended and generously shared by Hongkui Zeng at the Allen Institute for Brain Science; JAX stock 023527 and 031562, respectively). Between P75 and P80 two-photon functional and structural images were taken of the cell bodies and blood vessels. The mouse was perfused at P87.
Source: Inhibitory specificity from a connectomic census of mouse visual cortex
The MICrONS dataset: data acquisition, alignment, segmentation, etc. Data source description and the data analysis process for the KLOE experiment
This dataset was acquired, aligned and segmented as part of the larger MICrONS project. The primary data resource is described in a separate publication, as well as the methods underlying dataset acquisition. We repeat some of the methodological details for the dataset here for convenience.